We decided to take a look at the architecture of the Android Kernel. We selected the panda configuration for no particular reason – any other configuration would have worked just as well. The kernel code is written in C and it is derived from the Linux kernel. So, our approach will work on any configuration of the generic Linux kernel, as well.
Now we all know that C/C++ is a complex language and so we expect the analysis to be hard. But that difficulty just refers to the parser. Armed with the Clang parser we felt confident and were pleased that we didn’t run into any issues. Our goal was to examine all the C/C++ source files that go in the panda configuration and to understand their inter-relationships. To do this, it was necessary to figure out what files are included or excluded from the panda build. And then there were issues dealing with how all the files were compiled, included and linked. That all took effort. The resulting picture showed how coupled the Linux kernel is.
First, let’s acknowledge that the Linux kernel is well-written. What goes into it is tightly controlled. Given its importance in the IT infrastructure of the world, that is just what one would hope. Let us also remember that many of the modularity mechanisms in use today were invented in Unix. The notion of device drivers that plug into an Operating System was popularized by Unix and is commonplace today. Application pipes were pioneered by Unix. And yet, the Linux kernel itself has poor modularity.
Part of the problem is that that when Unix/Linux kernels were developed programming language support for modularity was poor. For instance, C does not have the notion of an interface and so dependency inversion is not naturally supported (it is possible, however). And, Linux has no real modularity mechanisms to verify or enforce modularity
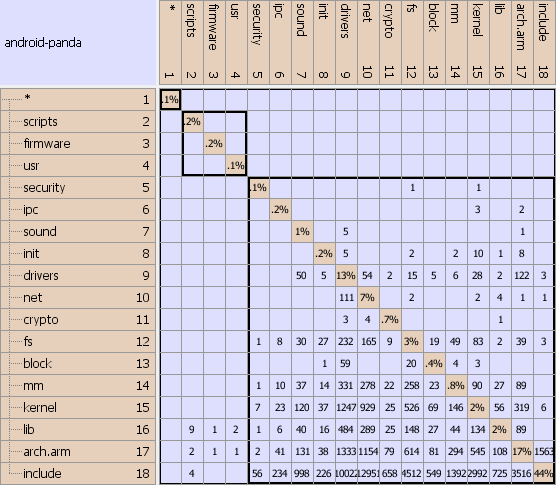
A few things become apparent after a partitioning algorithm is applied. This partitioning algorithm reorders the subsystems based on dependencies, revealing what is “lower” and what is “higher.” In an ideal implementation, the developers of the higher layer need only understand the API of the lower layers, while the developers of the lower layers need to worry about the higher layers only when an interface is affected. In a coupled system developers need to understand both layers making the job of understanding the impact of change considerably harder. Indeed, in the Android kernel where nearly all the layers are coupled, developers may sometimes have to understand thousands of files to feel confident about their changes.
This also means is that the intent behind the decomposition has been lost. For instance, ‘arch.arm’ is so strongly coupled with ‘kernel’ that it is hard for developers to understand one without understanding the other. Notice how even the ‘drivers’ are coupled to rest of the system. I experimented by creating a separate layer for the base layer of the drivers and I even moved some of the basic drivers such as ‘char’ and ‘tty’ and yet the coupling remained. Sadly, even some of the newer drivers are also coupled to the kernel.
All this goes to show that unless there is a focus on architecture definition and validation, even the best managed software systems will experience architectural erosion over time.
If you would like to discuss the methodology of this study or if you would like to replicate the results on your own, please contact me (neeraj dot sangal at lattix dot com). You can peruse a Lattix white paper on the Android kernel for some more details.